Книга «System Design. Подготовка к сложному интервью»

Привет, Хаброжители! Мы решили начинать продавать электронные книги до выхода бумажной книги. Начали с интервью по System Design (проектированию ИТ-систем), которые очень популярны у работодателей, на них легко проверить ваши навыки общения и оценить умение решать реальные задачи. Пройти такое собеседование непросто, поскольку в проектировании ИТ-систем не существует единственно правильных решений. Речь идет о самых разнообразных реальных системах, обладающих множеством особенностей. Вам могут предложить выбрать общую архитектуру, а потом пройтись по всем компонентам или, наоборот, сосредоточиться на каком-то одном аспекте. Но в любом случае вы должны продемонстрировать понимание и знание системных требований, ограничений и узких мест. Правильная стратегия и знания являются ключевыми факторами успешного прохождения интервью! Что внутри? — Инсайдерская информация: что на самом деле нужно интервьюерам — 4-х шаговый подход к решению любой задачи system design — 16 вопросов из реальных интервью с подробными решениями. — 188 диаграмм, наглядно объясняющих, как работают реальные системы.
Проектирование поискового робота
В этой главе мы сосредоточимся на интересной классической задаче, которую можно встретить на интервью по проектировании ИТ-систем, — создании поискового робота.
Поисковый робот еще называют веб-пауком или веб-краулером. Он широко используется в поисковых системах для обнаружения нового или обновленного контента в Сети. Это могут быть веб-страницы, изображения, видео, PDF-файлы и т. д. Сначала поисковый робот собирает несколько веб-страниц, а затем проходит по всем ссылкам, которые они содержат, чтобы собрать новый контент. Пример этого процесса показан на рис. 9.1.

Поисковый робот применяется для множества разных задач.
- Индексация в поисковой системе. Это самый распространенный сценарий использования. Робот собирает веб-страницы, чтобы создать локальный индекс для поисковой системы. Например, в поисковой системе Google эту роль играет Googlebot.
- Веб-архивация. Это процесс сбора информации с веб-страниц для дальнейшего хранения и использования. Например, архивацией веб-сайтов занимаются многие национальные библиотеки. В качестве известных примеров можно привести Библиотеку Конгресса США [1] и Веб-архив ЕС [2].
- Извлечение веб-данных. Сверхбыстрое развитие интернета создает беспрецедентную возможность для сбора информации. Извлечение веб-данных помогает собирать в Сети ценные сведения. Например, ведущие финансовые фирмы используют поисковые роботы для загрузки стенограмм собраний акционеров и ежегодных отчетов для анализа ключевых инициатив компании.
- Веб-мониторинг. Поисковые роботы помогают отслеживать нарушения авторских прав и незаконное использование торговых марок в интернете. Например, Digimarc [3] таким образом ищет пиратские копии и отчеты.
Шаг 1: понять задачу и определить масштаб решения
Поисковый робот работает по простому принципу:
- На вход подается список URL-адресов, после чего загружаются соответствующие веб-страницы.
- Из веб-страниц извлекаются URL-адреса.
- Новые URL-адреса добавляются в список для дальнейшей загрузки. Эти три шага повторяются заново.
Кандидат: «Каково основное назначение поискового робота? Он используется для индексации в поисковой системе, сбора данных или для чего-то другого?»
Интервьюер: «Для индексации в поисковой системе».
Кандидат: «Сколько веб-страниц поисковый робот собирает в месяц?»
Интервьюер: «1 миллиард страниц».
Кандидат: «Какого рода контент мы ищем? Только HTML или другие ресурсы вроде PDF-файлов и изображений?»
Интервьюер: «Только HTML».
Кандидат: «Следует ли учитывать недавно добавленные или отредактированные веб-страницы?»
Кандидат: «Нужно ли хранить собранные HTML-страницы?»
Интервьюер: «Да. Срок хранения — 5 лет».
Кандидат: «Что делать с веб-страницами, содержимое которых дублируется?»
Интервьюер: «Их следует игнорировать».
Это лишь некоторые из тех вопросов, которые можно задать интервьюеру. Необходимо разобраться в требованиях и прояснить непонятные моменты. Даже если вас попросят спроектировать такой простой продукт, как поисковый робот, у вас с интервьюером может быть разное понимание того, что он должен собой представлять.
Помимо функциональности, которую нужно согласовать с интервьюером, необходимо учитывать следующие характеристики поискового робота.
- Масштабируемость. Интернет огромен. В нем миллиарды веб-страниц. Поисковый робот должен быть чрезвычайно эффективным и использовать параллельные вычисления.
- Устойчивость. Интернет полон ловушек. Вам постоянно будет встречаться некорректный HTML-код, неотзывчивые серверы, сбои, вредоносные ссылки и т. д. Поисковый робот должен справляться со всеми этими пограничными случаями.
- Вежливость. Поисковый робот не должен отправлять веб-сайту слишком много запросов за короткий промежуток времени.
- Расширяемость. Система должна быть гибкой, чтобы для поддержки новых видов контента не приходилось вносить масштабные изменения. Например, если в будущем нам понадобится собирать графические файлы, это не должно привести к переработке всей системы.
Следующие оценки основаны на множестве предположений, поэтому вы должны убедиться в том, что вы с интервьюером правильно поняли друг друга.
Предположим, что каждый месяц загружается 1 миллиард веб-страниц.
QPS: 1 000 000 000 / 30 дней / 24 часа / 3600 секунд = ~400 страниц в секунду.
Пиковый показатель QPS = 2 * QPS = 800.
Предположим, что средний размер веб-страницы составляет 500 Кб.
1 миллиард страниц * 500 Кб = 500 Тб в месяц для хранения. Если вы плохо ориентируетесь в единицах измерения данных, перечитайте раздел «Степень двойки» в главе 2.
Если данные хранятся на протяжении пяти лет, 500 Тб * 12 месяцев * 5 лет = 30 Пб. Для контента, собранного за пять лет, нужно хранилище размером 30 Пб.
Шаг 2: предложить общее решение и получить согласие
Определившись с требованиями, мы переходим к общим архитектурным вопросам. На рис. 9.2 изображена предлагаемая архитектура, вдохновленная исследованиями [4] [5].
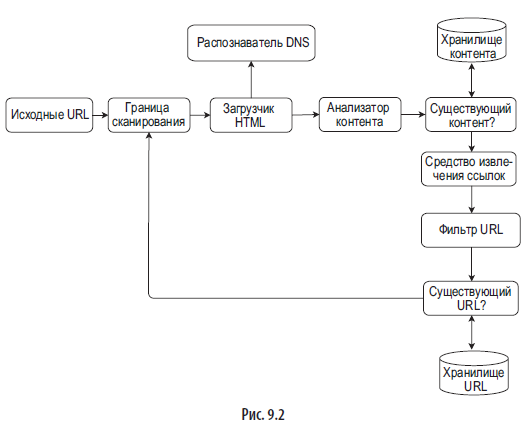
Исходные URL-адреса
В процессе поиска в качестве отправной точки используются исходные URL-адреса. Например, чтобы перебрать все веб-страницы на университетском веб-сайте, нам, очевидно, следует начать с доменного имени университета.
Для обхода всего интернета нам нужно творчески подойти к выбору исходных URL-адресов. Хороший исходный URL-адрес позволит перебрать как можно большее количество ссылок. Общая стратегия — разделить пространство адресов на отдельные части. Первый предложенный подход основан на местоположении, так как популярность тех или иных веб-сайтов может зависеть от страны. Исходные URL-адреса также можно выбирать по тематике. Например, адресное пространство можно разделить на покупки, спорт, медицину и т. д. Выбор исходных URL-адресов зависит от разных факторов. От вас не ожидают идеального решения. Просто размышляйте вслух.
Граница сканирования
Большинство современных поисковых роботов делят контент на уже загруженный и ожидающий загрузки. Компонент, хранящий URL-адреса, предназначенные для загрузки, называется границей сканирования. Его можно считать очередью вида «первым пришел, первым ушел». Углубленную информацию об этом компоненте можно найти в разделе, посвященном углубленному проектированию.
Загрузчик HTML
Этот компонент загружает веб-страницы из интернета. URL-адреса этих веб-страниц предоставляются границей сканирования.
Распознаватель DNS
Чтобы загрузить веб-страницу, URL сначала нужно перевести в IP-адрес. Для этого загрузчик HTML может обратиться к распознавателю DNS. Например, по состоянию на 5.3.2019 URL www.wikipedia.org преобразуется в IP-адрес 198.35.26.96.
Анализатор контента
После загрузки веб-страницы ее нужно проанализировать: вдруг у нее некорректный HTML-код, который вызовет проблемы и только займет место в хранилище? Если разместить анализатор контента на одном сервере с поисковым роботом, это замедлит процесс сбора данных. В связи с этим он имеет вид отдельного компонента.
Существующий контент?
Как показывает онлайн-исследование [6], 29 % от всех веб-страниц являются дубликатами, что может привести к повторному сохранению одного и того же контента. Мы используем структуру данных «Существующий контент?», чтобы избежать дублирования информации и сократить время обработки. Она помогает обнаруживать новый контент, который система уже сохраняла. Но это медленный подход, занимающий много времени, особенно если речь идет о миллиардах веб-страниц. Для эффективного выполнения этой задачи следует сравнивать не сами веб-страницы, а их хеши [7].
Хранилище контента
Это система хранения HTML. Ее выбор зависит от таких факторов, как тип и размер данных, частота доступа, время жизни и т. д. Используется как диск, так и память.
Большая часть контента хранится на диске, так как набор данных слишком большой и не умещается в памяти.
Востребованный контент хранится в памяти для снижения латентности.
Средство извлечения ссылок
Этот компонент анализирует HTML-страницы и извлекает из них ссылки. Пример этого процесса показан на рис. 9.3. Относительные пути преобразуются в абсолютные URL-адреса путем добавления префикса en.wikipedia.org.

Фильтр URL-адресов
Фильтр URL-адресов отклоняет определенные типы контента, расширения файлов, ссылки на страницы с ошибками и URL-адреса, занесенные в черный список.
Существующий URL-адрес?
«Существующий URL-адрес?» — это структура данных, которая отслеживает URL-адреса, которые уже посещались или находятся в границе сканирования. Это помогает избежать повторного открытия одного и того же URL-адреса, которое чревато повышенной нагрузкой на сервер и потенциальными бесконечными циклами.
Для реализации этого компонента обычно применяют такие методики, как фильтр Блума и хеш-таблица. Мы не станем в них углубляться. Дополнительную информацию можно найти в справочных материалах [4] [8].
Хранилище URL-адресов
Это хранилище уже посещенных URL-адресов.
Итак, мы рассмотрели каждый отдельный компонент. Теперь мы соберем их воедино и обсудим принцип работы системы в целом.
Принцип работы поискового робота
Чтобы как следует объяснить каждый этап рабочего процесса, мы добавили на диаграмму архитектуры порядковые номера (рис. 9.4).
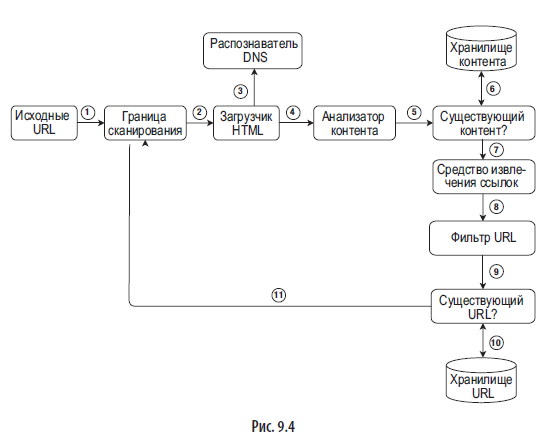
Шаг 1. Добавляем исходные URL-адреса в границу сканирования.
Шаг 2. Загрузчик HTML берет список URL-адресов из границы сканирования.
Шаг 3. Загрузчик HTML получает соответствующие IP-адреса от распознавателя DNS и начинает загрузку.
Шаг 4. Анализатор контента разбирает HTML-страницы и проверяет их корректность.
Шаг 5. После разбора и проверки контент передается компоненту «Существующий контент?».
Шаг 6. Компонент «Существующий контент?» проверяет, есть ли данная HTML-страница в хранилище:
- если есть, это означает, что этот контент находится по другому URL-адресу и мы его уже обработали. В этом случае HTML-страница отклоняется;
- если нет, система еще не обрабатывала этот контент, поэтому он передается средству извлечения ссылок.
Шаг 8. Извлеченные ссылки передаются фильтру URL-адресов.
Шаг 9. После фильтрации ссылки передаются компоненту «Существующий URL-адрес?».
Шаг 10. Компонент «Существующий URL-адрес?» проверяет, находится ли URL в хранилище. Если да, то он уже обрабатывался и больше ничего делать не нужно.
Шаг 11. Если URL-адрес еще не обрабатывался, он добавляется в границу сканирования.
Более подробно с книгой можно ознакомиться на сайте издательства
Оформить предзаказ бумажной книги по специальной цене можно на нашем сайте.
При покупке бумажной книги будет доступно чтение онлайн.
https://habr.com/ru/companies/piter/articles/598791/